

Hi everyone!
I want to share with you how I built a Node.js API for one of our biggest clients, where I will describe some patterns and javascript conventions I've used. I will make it easy to export these ideas elsewhere so they can be useful for your projects.
I will break down this guide into several parts. My goal with this series posts is to make it easy to understand the rationale behind my decisions regarding code structure and conventions.
Disclaimer: the source code examples are, in most of the cases, a simplification of the real code for easier legibility and to avoid compromising our client's code.
Part 1: Overview, setup, and database
The stack
We decided to split the application into two layers, http and database:
- express: the web framework (for ruby-ists, it's like Sinatra).
- objection: a simple ORM for node.js (based on knex, a SQL query builder).
Then, we've added a bunch of really useful libraries:
- joi: object schema validation. Used, for example, to validate request parameters.
- passport: handles user authentication (in this case, it handles JWT logic).
- helmet: middleware helping with HTTP security issues.
- agenda: background jobs with a MongoDB backend.
- nodemailer: email sending.
Code organization
When developing express.js apps, there are no enforced or even recommended ways to structure apps. You can use controllers, for example, but it's up to you.
Our CTO, Xavi, gave me an advice that I'm following (partially 😂): "choose an organisation model and stick to it". It's a good and pragmatic advice, but I have to confess that I can't apply it fully because I feel it constrains too much the natural code evolution. Anyway, my current structure is as follows:
app
models
services
lib
http
middleware
routes
controllers
requests
responses
database
migrations
seeds
config
There are three root folders: app, database and config. The most important one is, obviously, app, containing:
- models: where we store all the database models. I feel that having all models together helps a lot to understand the domain model at a glance, and therefore, to understand the app faster.
- services: it contains all the business logic. With this structure, there is no logic inside models. All logic, even queries, is inside services. So services are the most important part of the app and where most of the logic lives.
- lib: contains all logic that has no dependency on models. For example, the rules orchestrating the different Process states live here. Other kinds of code not related to business logic, but specific to the app also live here: I have my own decorated version of the "fetch" method that works out of the box with https and json and mocking support. Another example: a function to interpolate values into a string. It extends a library with new features. Eventually, you could publish that as an npm package if you find this is useful outside your app.
- http: it contains all code related to transporting information. Routes and controllers are well known in Ruby-land, but I use also middleware (shared functionality, like authentication and authorization), requests (param validation) and responses (convert database data into API responses).
File names convention
There's no standard way to name files in javascript but the following convention fits well with my workflow. Further, it's easy to find files using the editor and you know what are you seeing because of their filenames.
I'm using snake case to name the thing, following, if required, by a dot with its type. Some examples:
- A "Process" model: /app/models/process.model.js
- A "StageAction" controller: /app/http/controllers/stage-action.controller.js
- A "StageAction" service: /app/services/stage-action.service.js
Sometimes a file gets too long (I'm looking at you, services) so I split it into several files and use the node ability to load the "index.js" file if none is provided. For example:
/app/services/stage-action.service
index.js
run-action.js
validate-params.js
...
The index file is something like this:
const runAction = require('./run-action);
const validateParams = require('./validate-params);
module.exports = { runAction, validateParams }
The good part is that I don't have to change the "require" statement. Everything works out of the box:
const StepActionService = require("./app/services/stage-action");
StageActionService.runAction(...);
Anatomy of a request
As an overview, when a request arrives it works as follows:
- A router decides what middleware and controller to run (there's a default error middleware that is executed if none is found).
- Some middleware is executed. For example, to verify the JWT token. Or, depending on the request, it could validate params or authorise some actions.
- A controller is executed. A controller basically takes the parameters from the request and calls a service with those parameters.
- A service is executed. It may use other services or perform the task. It may use a model to perform queries.
- After a service is executed the controller takes the output and hands it to a response. The response maps the result to the expected API data structure.
Database
There are several options to access a SQL database in Node.js, but none of them is particularly outstanding (like ActiveRecord in Rails). Part of the reason is that a lot of Node.js projects use MongoDB as backend (and there some decent ORM for that noSQL database).
Basically, to access a SQL database there are two popular solutions:
- On the one side, sequelize, a complete and, in my opinion, over-complex ORM
- On the other side the minimalistic knexjs, a simple and barebone SQL builder
I've chosen a thin layer over knex (objection.js) which helps with the model definition and its relations.
Configuration and initialisation
First of all, I've added a knex.js configuration file inside the /config folder. Something like this:
const MarsBasedDB = {
client: "mssql",
connection: {
database: "process",
user: "user-here",
password: "password-here",
server: "server-here",
port: "1433",
options: {
tdsVersion: "7_1"
}
},
migrations: {
directory: "../migrations"
},
seeds: {
directory: "../seeds"
}
};
const ClientDB = {
client: "mssql",
connection: {
database: "db-here"
user: "user-here"
...
},
...
}
module.exports = {
development: MarsBasedDB,
test: MarsBasedDB,
production: ClientDB
}
The difference between the development and production database is that the latter will try to get the values from the environment (using process.env) with some valid defaults. As you can see, the knex configuration accepts migration and seed directories (more on that later).
Theory looks good, but what happens in practice, namely, in real life?
RealLife™: environment variables are extracted and exposed to the app in a different place (/config/variables.js) where the valid default values are added. The database configuration uses this variables.js file to get the actual values.
The next step is to create a connection and pass it to objection so models know what database to use when performing queries and updates.
I've added the following /database/index.js file:
const Knex = require("knex");
const { Model } = require("objection");
const knexConfig = require("../config/knex.js");
function connect(env) {
const config = knexConfig[env];
if (!config) {
throw Error(`Database connect error: invalid environment ${env}`);
}
const knex = Knex(config);
// Bind all models to the knex instance
Model.knex(knex);
return knex;
}
module.exports = connect;
I can create a connection like this:
const db = require("../database")("development");
// perform some stuff
...
// close the database connection
db.destroy();
RealLife™: our client's Process entity uses two databases, so a little complexity adds up on this side. Also, a different interface to create and destroy database connections (more OOP) is implemented to simplify testing.
Models
Models have a different approach in objection.js than ActiveModel. In objection.js a model is a definition of the model itself but no model instances are created. When you perform a query using objection, each row in the database is mapped to a standard javascript object that follows the definition you provide. In ActiveModel, on the contrary, each row is mapped to an instance of the model object.
Suppose the following model (a simplification of what I have): a Process has several Stages and each Stage can have several Actions to be executed. There's also the concept of Roles, which is used to know which Users can view or execute Actions on each Step of the Process:
This is our simplified data model for this project
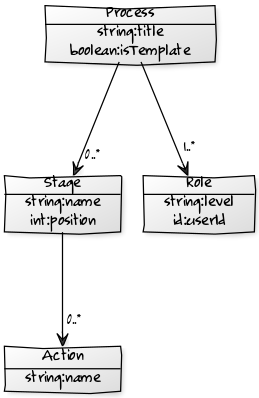
RealLife™: obviously, the data model is more complex, but we have simplified it here for reading purposes and, again, to obfuscate client data.
The Process model is something like this:
const { Model } = require("objection");
class Process extends Model {
static get tableName() {
return "processes";
}
static get jsonSchema() {
return {
type: "object",
properties: {
id: { type: "integer" },
name: { type: "string" },
state: { type: "string" },
...
created_on: { type: "string", format: "date-time" },
updated_on: { type: "string", format: "date-time" }
}
};
}
static get relationMappings() {
return {
stages: {
relation: Model.HasManyRelation,
modelClass: require("./stage.model"),
join: {
from: "processes.id",
to: "stages.process_id"
}
},
roles: {
relation: Model.HasManyRelation,
modelClass: require("./role.model"),
join: {
from: "processes.id",
to: "process_roles.process_id"
}
},
};
}
$beforeInsert() {
this.created_on = new Date().toISOString();
}
$beforeUpdate() {
this.updated_on = new Date().toISOString();
}
}
module.exports = Process;
All of the above is quite self-explanatory. The tableName, jsonSchema and relationMappings static methods belong to the objections.js API and are only required if you want to define a database Model with relations. JSON Schema is a (semi-standard) way to define the shape of javascript objects. Objection has the concept of hooks (methods that are called at some points of a process) and all of them use the name convention of starting with a $ sign.
A note on Dates: I chose to store dates using strings to have control of the timezone used to store the Date (I use UTC via Date's toISOString method). You can read at jsonSchema method that objection will try to validate the string using the standard "date-time" format.
Relations
On the other hand, a Role model is something like this:
const { Model } = require("objection");
class Role extends Model {
static get tableName() {
return "process_roles";
}
static get jsonSchema() {
return {
type: "object",
properties: {
id: { type: "integer" },
level: { type: "string", enum: ["view", "update"] },
process_id: { type: "integer" },
user_id: { type: "integer" },
...
}
};
}
static get relationMappings() {
return {
process: {
relation: Model.BelongsToOneRelation,
modelClass: require("./process.model"),
join: {
from: "process_roles.process_id",
to: "processes.id"
}
}
};
}
}
module.exports = Role;
As you can see, there's a circular dependency between both files: process.model requires role.model and vice-versa. That's why the "require" statement is inside the relationMappings function (something I don't like about objection, but there's no other way to solve it).
Circular dependencies are a code smell and to require inside methods is a known JS bad practice (but there's some much we can do about it for now. UPDATE: read Require loops for more options).
Queries
Objection itself is not an ORM but it has quite powerful SQL builder capabilities (in fact, most of them are provided by knex, the underlying library). For example, it is normal to have queries as conditions of where clauses:
function getUserProcessess(userId) {
return Role.query()
.where('user_id', userId)
.select('process_id');
}
function getActiveStages(processIds) {
return Role.query()
.where('state', 'active')
.whereIn('process_id', processessIds);
}
const activeStagesForUser1 = getActiveStages(getUserProcesses(1));
Because the results are not models objects themselves, you can NOT query for an object and then use the resulting model to fetch more objects, like you'd do in Rails:
# ActiveRecord code ruby code
process = Process.find(1);
process.stages
With objection, we try to do everything in a single query:
const process = Process.query()
.where('id', 1)
.eager('stages');
process.stages // => an array of stages
UPDATE: As Sami Koskimäki (the creator of objection.js) points out in the comments, I was wrong and query results are model objects themselves, so you can interact with them to follow the relations. Anyway, I'm still happy with the approach of retrieve everything in a single query. On the opposite direction, the awesome upsertGraphh function allows to update a graph of models with a single call.
Migrations and seeds
Finally, the knex library provides database migration (and database seed) mechanism. Migrations are easy to write and run, and I store them all inside /database/migrations folder. Here's an example:
function up(knex) {
return knex.schema.createTable("participants", table => {
table.increments();
table
.integer("process_id")
.unsigned()
.index();
table.integer("user_id").unsigned();
table.string("level", 32);
table.timestamps();
});
}
function down(knex) {
return knex.schema.dropTableIfExists("participants");
}
module.exports = { up, down }
Next part
This is it for the first part of our how to create APIs in Node.js guide!
In the second part, we will move to express, talk about middleware, how to organize routes and controllers, and write the business logic using services.
Stay tuned!
Related articles

How we actually use AI to build software: what's in the Handbook's AI-Augmented Development page
A few months ago we quietly added a new section to the MarsBased Handbook laying out exactly how we use Claude Code day to day, from research to planning to implementation. We never wrote about it here, so we're fixing that now.
Read full article
Using AI to run performance reviews: how we evaluate our team with Claude
How we connected Claude to our remote stack to eliminate bias and bureaucracy from performance reviews, while keeping human judgment firmly at the center.
Read full article
How MarsBased integrates AI across development and operations
At MarsBased, AI has become part of our daily workflow: from how developers write code to how non-technical teams create, translate, and manage content. Here’s a look at how we’re Claude Code and similar tools to improve efficiency across the entire company.
Read full article